
📌 준비하기
- 'northwind database' 를 활용하여 실습하였습니다.
- 아래의 링크에서 확인하거나 [여기]를 클릭하여 쿼리문을 볼 수 있습니다.
GitHub - microsoft/sql-server-samples: Azure Data SQL Samples - Official Microsoft GitHub Repository containing code samples for
Azure Data SQL Samples - Official Microsoft GitHub Repository containing code samples for SQL Server, Azure SQL, Azure Synapse, and Azure SQL Edge - GitHub - microsoft/sql-server-samples: Azure Dat...
github.com
- 아래의 쿼리문을 실행합니다.
- 'northwind database' 데이터베이스의 Orders 테이블을 'TestOrders'라는 테이블로 생성하여 복사합니다.
- 더미 데이터를 늘리기위해 while문으로 복사하여 생성한 후 개수를 확인하면 83만개가 나옵니다.
--step1 Orders테이블을 TestOrders에 복사
select *
into TestOrders
from Orders;
--step2 더미 데이터를 늘리기
declare @i int = 1;
declare @emp int;
select @emp = MAX(EmployeeID) from Orders;
while(@i < 1000)
begin
insert into TestOrders(CustomerID, EmployeeID, OrderDate)
select CustomerID, @emp + 1, OrderDate
from Orders;
set @i = @i + 1;
end
-- step3 더미 데이터가 삽입된 테이블의 튜플개수 확인 (83만개)
select count(*)
from TestOrders;
📌 복합인덱스 생성
- 복합 인덱스를 두개 생성합니다.
- 하나는 EmployeeID, OrderDate 순서, 다른 하나는 OrderDate, EmployeeID 순서로 생성합니다.
-- step4 논클러스터 복합 인덱스 두개를 생성
create nonclustered index idx_emp_ord -- employeeID, orderDate 순서
on TestOrders(employeeID, orderDate);
create nonclustered index idx_ord_emp -- orderDate, employeeID 순서
on TestOrders(orderDate, employeeID);
📌 통계 활성화
- 더욱 정확한 분석을 위해 통계를 활성화합니다.
-- step5 메시지 통계 디테일 활성화
set statistics time on;
set statistics io on;
📌 분석
· case 1
- 두개의 인덱스를 이용하여 equal 연산으로 각각 검색합니다.
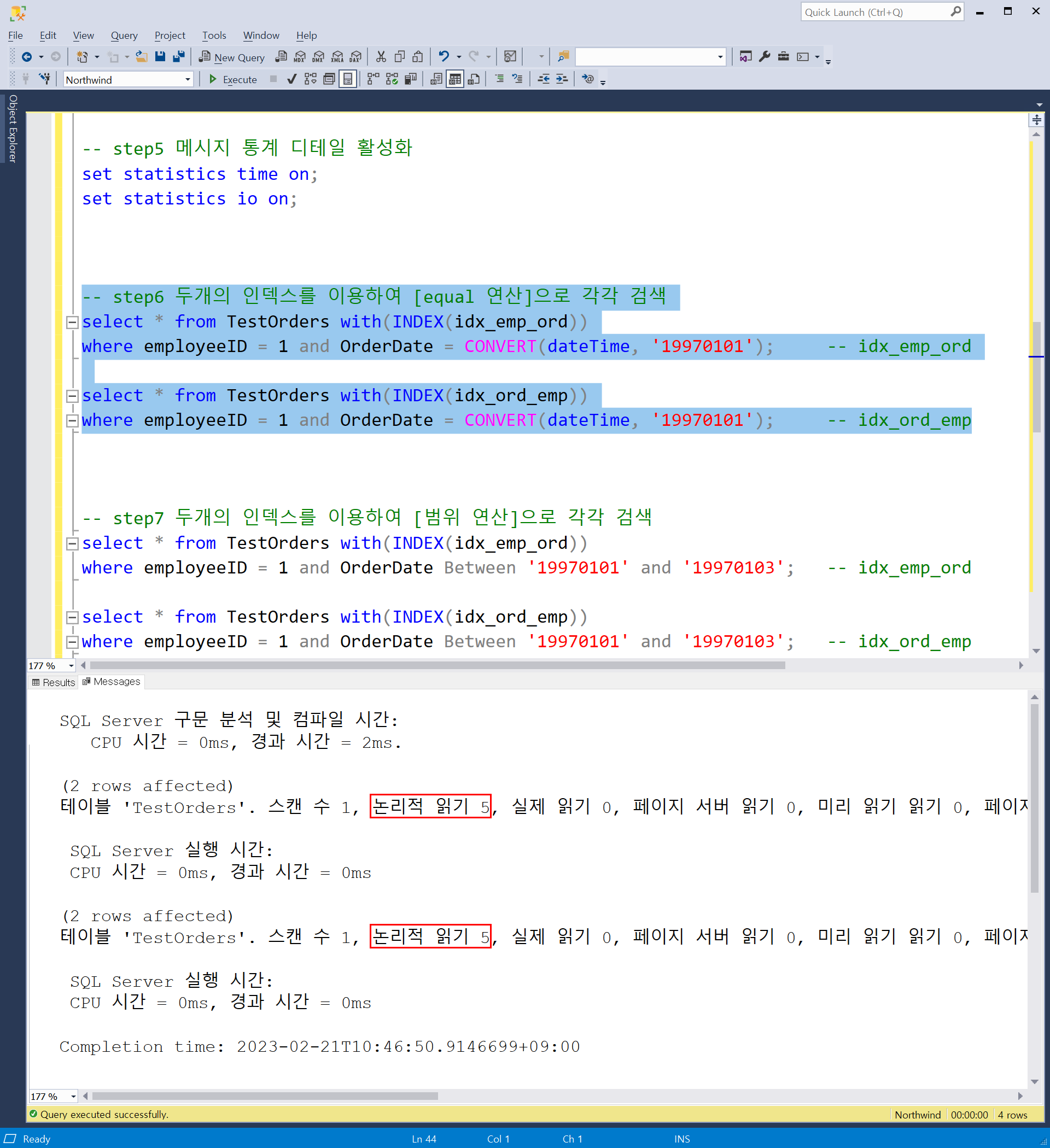
- 복합 인덱스의 순서가 바뀌어도 논리적 읽기의 수는 같게나와 성능은 동일하게 나타났습니다.
· case 2
- 두개의 인덱스를 이용하여 범위연산을 통해 검색을 합니다.
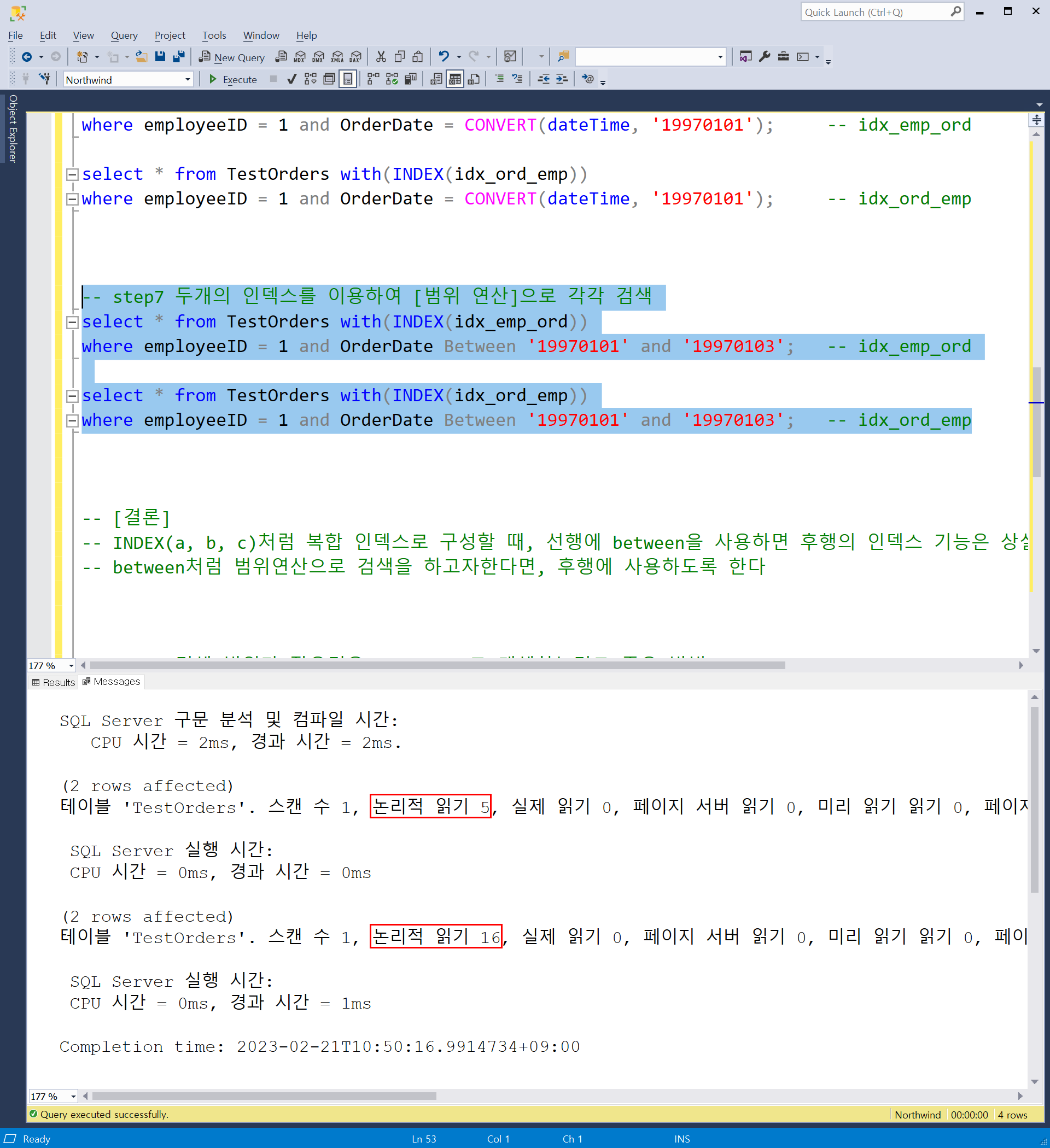
- idx_emp_ord를 사용한 검색에서는 선행에 equal, 후행에 범위연산을 하였습니다. 논리적 읽기 수는 5가 나왔습니다.
- idx_emp_ord를 사용한 검색에서는 선행에 범위, 후행에 equal을하였습니다. 논리적 읽기 수는 16이 나왔습니다.
👍 결론
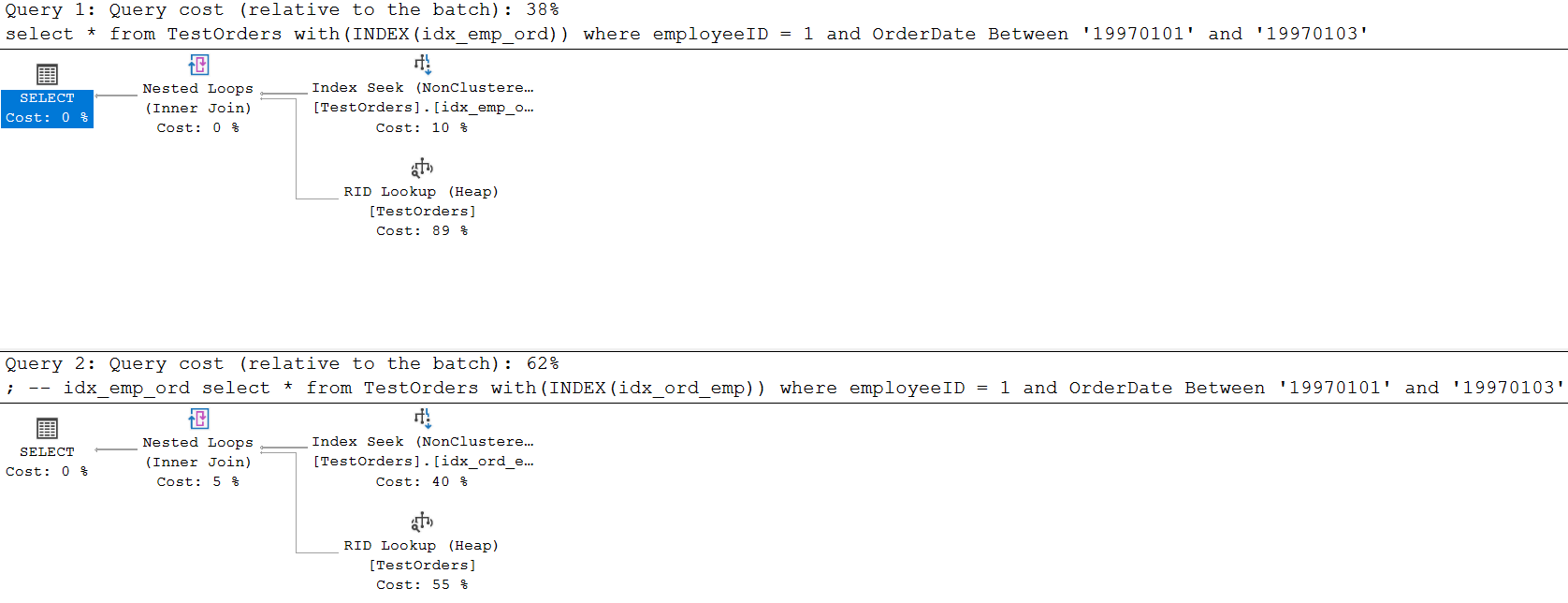
- INDEX(a, b, c)처럼 복합 인덱스로 구성할 때, 선행에 between을 사용하면 후행의 인덱스 기능은 상실합니다.
- between처럼 범위연산으로 검색을 하고자한다면, 후행에 사용하는것이 좋습니다.
📌 추가사항
· IN - LIST
- 검색 범위가 작은경우 in (LIST)로 대체하는것도 좋은 방법입니다.
- 후행의 인덱스 기능을 상실할때 사용 고려 가능합니다.
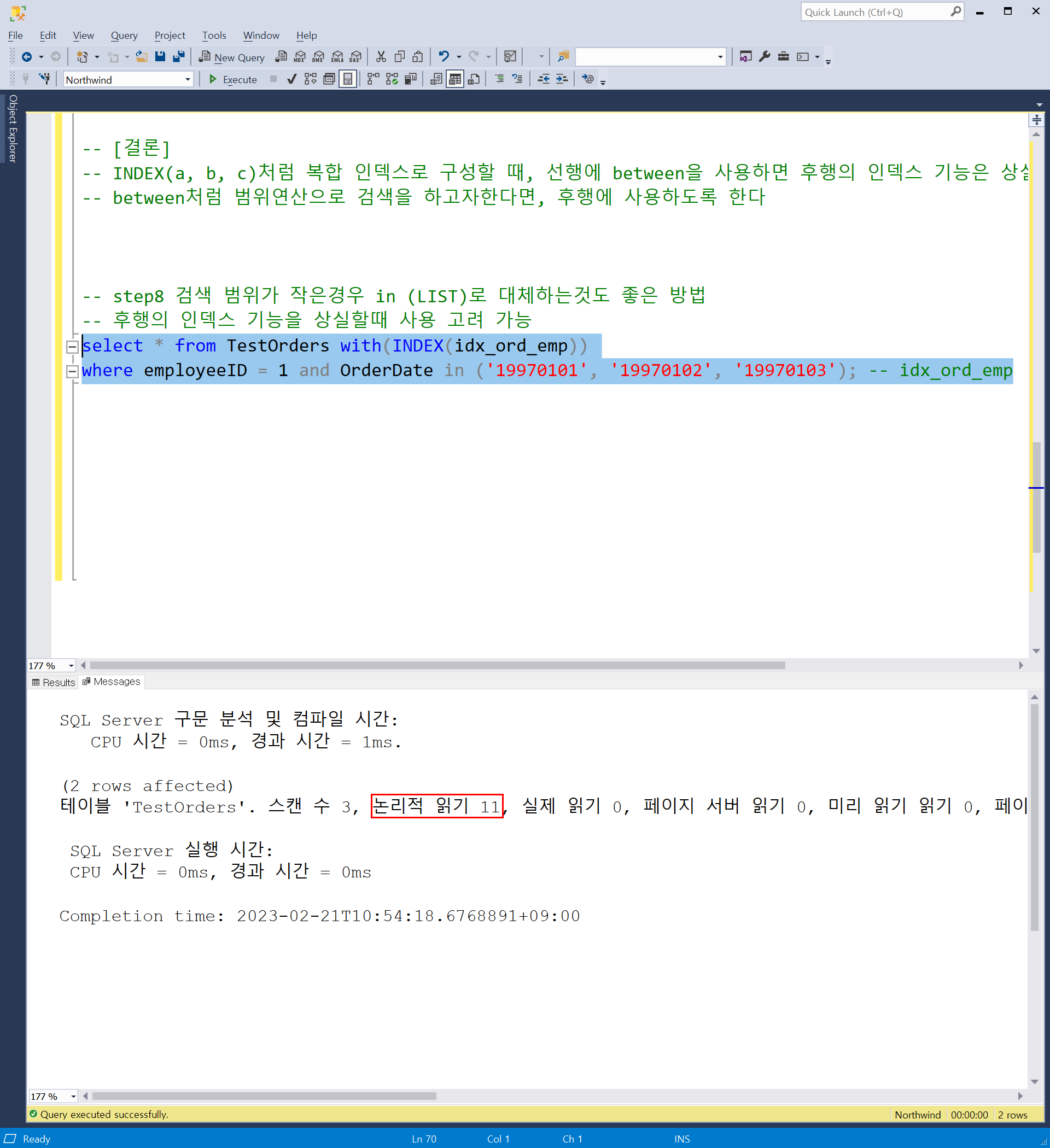
- 같은 연산이지만, 직전 연산에서의 논리적읽기 16에서 11로 감소한것을 볼 수 있습니다.
👍 최종결론
- 복합 칼럼 인덱스 (선행, 후행) 순서가 영향을 줄 수 있다.
- 범위 연산(between, <>)가 선행에 들어가면 후행의 인덱스 기능을 상실
- between의 범위가 작으면 in (LIST)로 고려할 수 있다 (항상 좋은것은 아님!)
- 후행의 인덱스 기능을 상실한것이 아니라면 in (LIST)는 오히려 낭비
'db' 카테고리의 다른 글
| [MSSQL] CREATE ALTER DROP (0) | 2023.02.21 |
|---|---|
| [redis] 실습 준비 (0) | 2023.02.21 |
| [MSSQL] SUB QUERY (0) | 2023.02.21 |
| [MSSQL] INSERT DELETE UPDATE (0) | 2023.02.21 |
| [MSSQL] 복합 인덱스 (0) | 2023.02.20 |
📌 준비하기
- 'northwind database' 를 활용하여 실습하였습니다.
- 아래의 링크에서 확인하거나 [여기]를 클릭하여 쿼리문을 볼 수 있습니다.
GitHub - microsoft/sql-server-samples: Azure Data SQL Samples - Official Microsoft GitHub Repository containing code samples for
Azure Data SQL Samples - Official Microsoft GitHub Repository containing code samples for SQL Server, Azure SQL, Azure Synapse, and Azure SQL Edge - GitHub - microsoft/sql-server-samples: Azure Dat...
github.com
- 아래의 쿼리문을 실행합니다.
- 'northwind database' 데이터베이스의 Orders 테이블을 'TestOrders'라는 테이블로 생성하여 복사합니다.
- 더미 데이터를 늘리기위해 while문으로 복사하여 생성한 후 개수를 확인하면 83만개가 나옵니다.
--step1 Orders테이블을 TestOrders에 복사
select *
into TestOrders
from Orders;
--step2 더미 데이터를 늘리기
declare @i int = 1;
declare @emp int;
select @emp = MAX(EmployeeID) from Orders;
while(@i < 1000)
begin
insert into TestOrders(CustomerID, EmployeeID, OrderDate)
select CustomerID, @emp + 1, OrderDate
from Orders;
set @i = @i + 1;
end
-- step3 더미 데이터가 삽입된 테이블의 튜플개수 확인 (83만개)
select count(*)
from TestOrders;
📌 복합인덱스 생성
- 복합 인덱스를 두개 생성합니다.
- 하나는 EmployeeID, OrderDate 순서, 다른 하나는 OrderDate, EmployeeID 순서로 생성합니다.
-- step4 논클러스터 복합 인덱스 두개를 생성
create nonclustered index idx_emp_ord -- employeeID, orderDate 순서
on TestOrders(employeeID, orderDate);
create nonclustered index idx_ord_emp -- orderDate, employeeID 순서
on TestOrders(orderDate, employeeID);
📌 통계 활성화
- 더욱 정확한 분석을 위해 통계를 활성화합니다.
-- step5 메시지 통계 디테일 활성화
set statistics time on;
set statistics io on;
📌 분석
· case 1
- 두개의 인덱스를 이용하여 equal 연산으로 각각 검색합니다.
- 복합 인덱스의 순서가 바뀌어도 논리적 읽기의 수는 같게나와 성능은 동일하게 나타났습니다.
· case 2
- 두개의 인덱스를 이용하여 범위연산을 통해 검색을 합니다.
- idx_emp_ord를 사용한 검색에서는 선행에 equal, 후행에 범위연산을 하였습니다. 논리적 읽기 수는 5가 나왔습니다.
- idx_emp_ord를 사용한 검색에서는 선행에 범위, 후행에 equal을하였습니다. 논리적 읽기 수는 16이 나왔습니다.
👍 결론
- INDEX(a, b, c)처럼 복합 인덱스로 구성할 때, 선행에 between을 사용하면 후행의 인덱스 기능은 상실합니다.
- between처럼 범위연산으로 검색을 하고자한다면, 후행에 사용하는것이 좋습니다.
📌 추가사항
· IN - LIST
- 검색 범위가 작은경우 in (LIST)로 대체하는것도 좋은 방법입니다.
- 후행의 인덱스 기능을 상실할때 사용 고려 가능합니다.
- 같은 연산이지만, 직전 연산에서의 논리적읽기 16에서 11로 감소한것을 볼 수 있습니다.
👍 최종결론
- 복합 칼럼 인덱스 (선행, 후행) 순서가 영향을 줄 수 있다.
- 범위 연산(between, <>)가 선행에 들어가면 후행의 인덱스 기능을 상실
- between의 범위가 작으면 in (LIST)로 고려할 수 있다 (항상 좋은것은 아님!)
- 후행의 인덱스 기능을 상실한것이 아니라면 in (LIST)는 오히려 낭비
'db' 카테고리의 다른 글
| [MSSQL] CREATE ALTER DROP (0) | 2023.02.21 |
|---|---|
| [redis] 실습 준비 (0) | 2023.02.21 |
| [MSSQL] SUB QUERY (0) | 2023.02.21 |
| [MSSQL] INSERT DELETE UPDATE (0) | 2023.02.21 |
| [MSSQL] 복합 인덱스 (0) | 2023.02.20 |